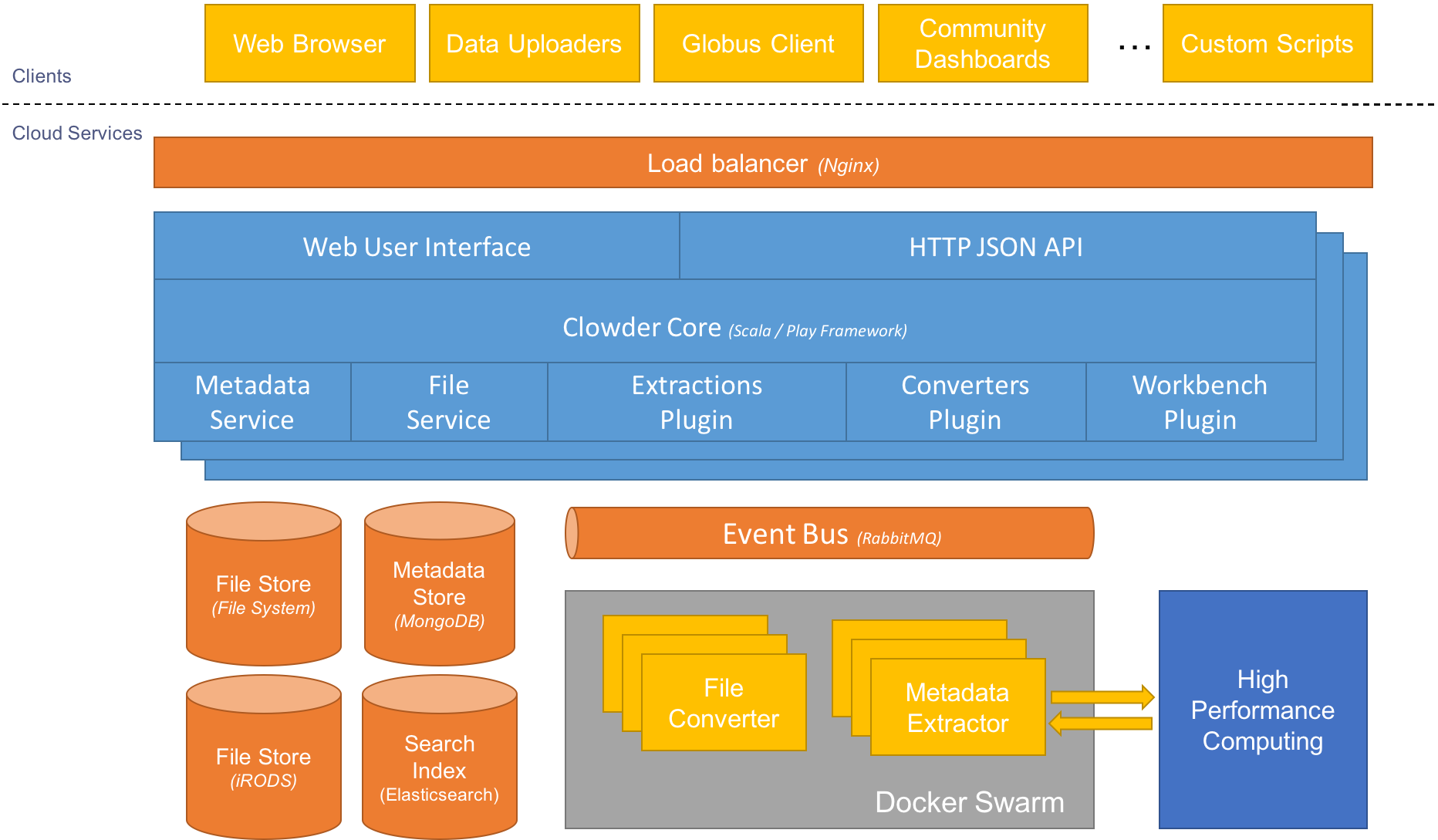
Architecture¶
Clowder’s architecture consists of typical front end web application and several backend services. A Web user interface is provided out of the box for users interacting with the system through a Web browser. An extensive Web service API is provided for external clients to communicate with the system. These clients can include custom GUIs for specific use cases as well as headless scripts for system to system communication.
A service layer abstracts backend services so that individual deployments can be customized based on available resources. For example a user might want to store raw files on the file system, MongoDB GridFS, iRods or AWS S3 buckets.
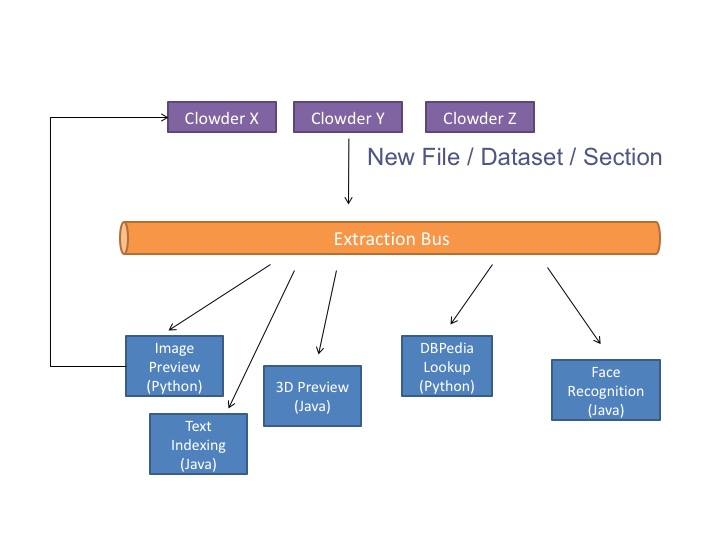
When new data is added to the system, whether it is via the web interface or through the RESTful API, preprocessing is off-loaded to extraction services in charge of extracting appropriate data and metadata. The extraction services attempt to extract information and run preprocessing steps based on the type of the data just uploaded. Extracted information is then written back to the repository using appropriate API endpoints.
For example, in the case of images, a preprocessing step takes care of creating the previews of the image, but also of extracting EXIF and GPS metadata from the image. If GPS information is available, the web client shows the location of the dataset on a map embedded in the page. By making the clients and preprocessing steps independent the system can grow and adapt to different user communities and research domains.